大疆POCKET 3拍摄糊糊的? 今天分享pocket3到手必做的9个设置[哇R] 包括参数设置、拍摄、后期[自拍R] 一篇带你把pocket3用回本 拍出超出片的冷白皮~
快速申请通道:https://b23.tv/mall-Vsrcg-74BWP 更多信息可移步视频置顶评论区 流量卡相关疑问,可私信up哦
v: 864768525 qq交流群:727455423
-
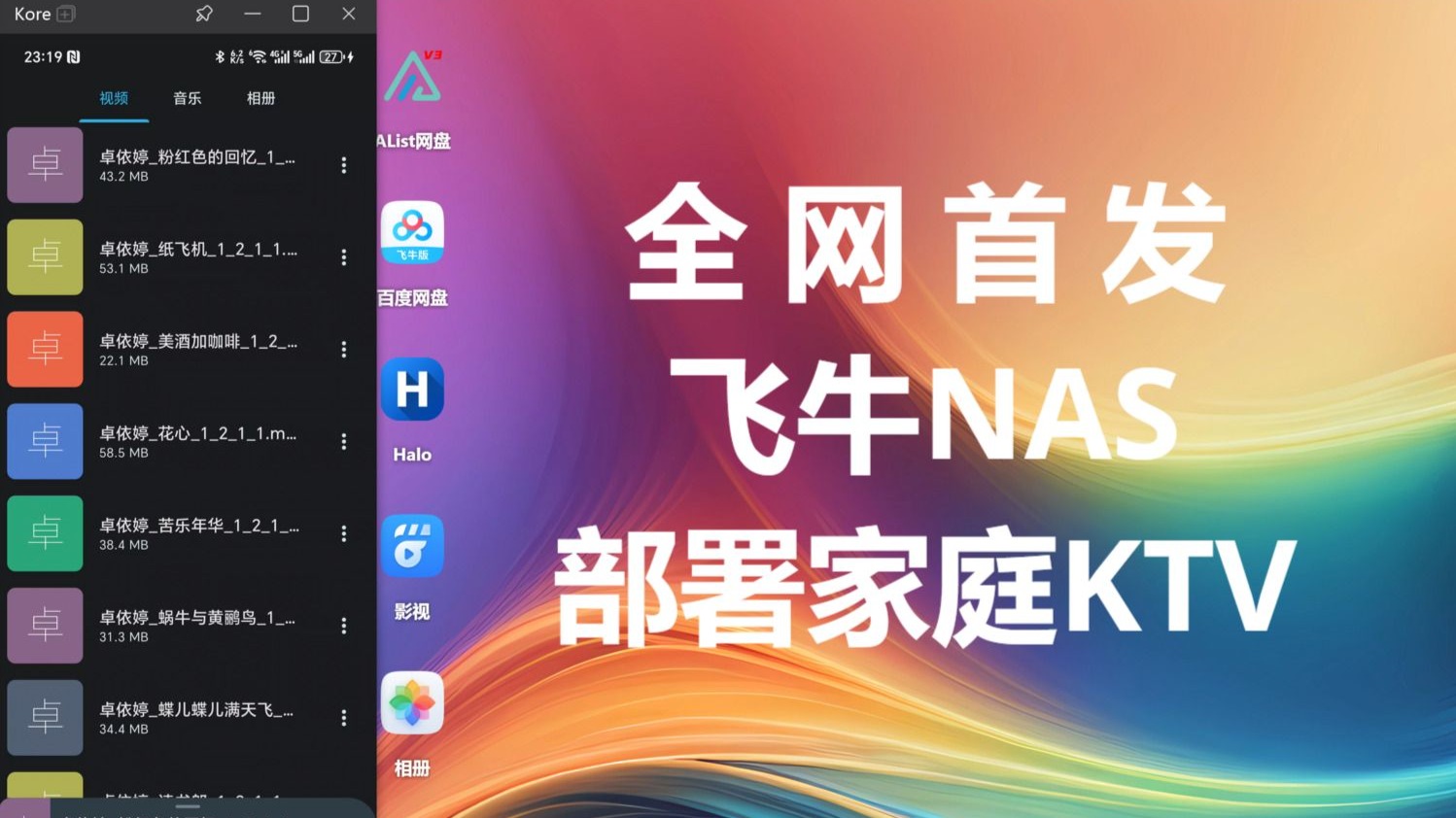
本期视频适用NAS端部署,手机端可以看我往期视频,三连后私信会自动回复所有用到的工具
这很不鸿蒙… 特别是用了澎湃OS3后,同样是岛,有自己思考加成的新逻辑就很惊喜,无论是动画还是体验都把鸿蒙这实况窗秒了。可能是我对鸿蒙前面表现那么好,就默认鸿蒙多多少少上居中实况窗得来点创新的变革,结果… 算了下次再展开跟大伙聊澎湃这个岛吧~
快速申请通道:https://b23.tv/mall-1Tbkc7-74LFY 更多信息可移步视频置顶评论区 流量卡相关疑问,可私信UP哦
大部分穿越机商拍最考验基本功 控高控速 花里 胡哨的自己玩玩
给机械手加点“鱼”味 | Festo 仿生自适应抓手
【简单评测】开学季入手笔记本?还得看看英特尔!几款我比较推荐的型号!
一英寸之战,相机对比手机还有优势吗?
仅需199起,真能干掉GPW? 雷柏VT1究竟有多强?
综合 0