https://www.youtube.com/watch?v=gYHI1ZVvaoA&t=456s Adeline3d
-
即将到来的好消息简要回顾: iPhone 17 Pro、iPhone Air(史上最薄的 iPhone)、iPhone 17、AirPods Pro 3、Apple Watch SE 3、Apple Watch Ultra 3,以及 Apple Watch Series 11。
家人们!B站刚开源的Index TTS2被我挖到了!ComfyUI两大插件作者火速更新2.0版本,时间精准控制+超丰富情感表达,直接吊打现有TTS模型!附整合包实测,显存24G轻松跑~喜欢的话欢迎点赞关注催更呦,任何问题欢迎在评论区留言,我看到的话都会回复,还有很多热心的大佬也会出手相助!你还可以在线体验最新AI应用👉https://www.runninghub.ai/user-center/1902003102638354434/webapp?inviteCode=59edf1e8https://ope
点UP头像或评论区留言,可免费解答所有建模软件安装及技术问题 如果你是新手小白,建议观看: 3Dmax 基础教程:BV1fW8EzCEzL MAYA 基础教程:BV19x7ez5Evp ZBrush 全版本安装教程:BV1FKfKYgESU SP 软件安装教程:BV1MhsWeTEmK Knald 软件安装教程:BV1WN8yzXETM 八猴(中文版)软件安装教程:BV1Tdj4zmEkD 100+款车辆3D模型源文件:BV1Ng4y1S7Fe 100+款次世代载具模型源文件:BV1mMhPzH
【2025最新PR教程】Premiere保姆级教程 | 影视剪辑零基础入门到精通教程 | PR影视后期制作 | 视频剪辑后期特效制作 | 系统教程全套
【PPT办公软件教程】PPT保姆级教程 | 手把手带你从小白到大神 | 职场办公软件精通教程 | 全程干货无废话 | B站最用心的office办公软件教程
Notion美化技巧与实用窍门
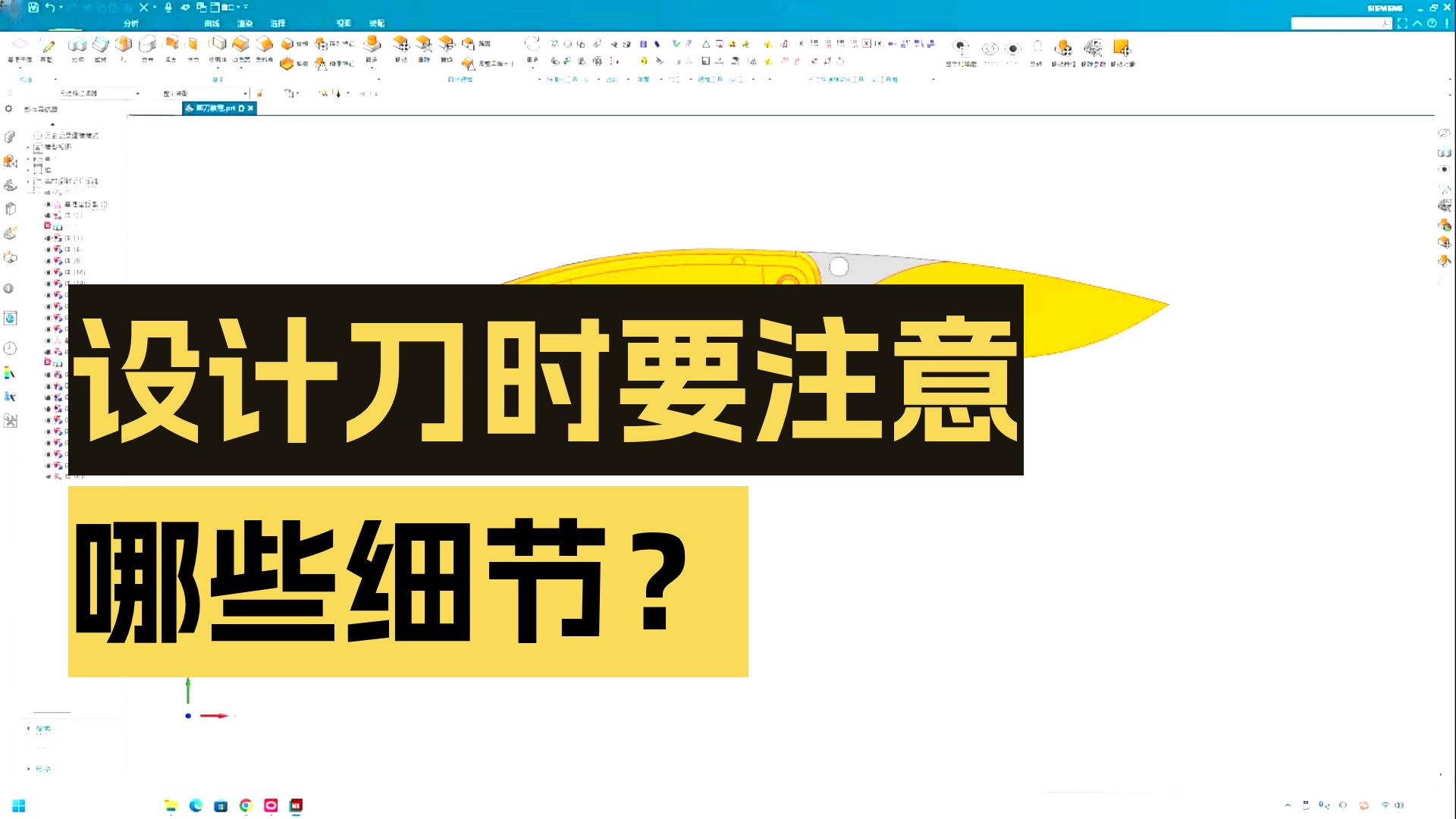
【3dmax建模】(iPhone 17)建模案例,零基础布线讲解,3dmax新手建模案例教学
给学员看代码直接把我电脑关机了
野生技能协会 0